Ollama 应用实践:文本嵌入(Embeddings)

Ollama 支持嵌入模型,从而可以构建将文本提示与现有文档或其他数据相结合的检索增强生成 (RAG) 应用程序。
什么是 Embedding 模型?
Embedding 模型是经过专门训练以生成向量嵌入的模型:表示给定文本序列的语义含义的长数字数组:
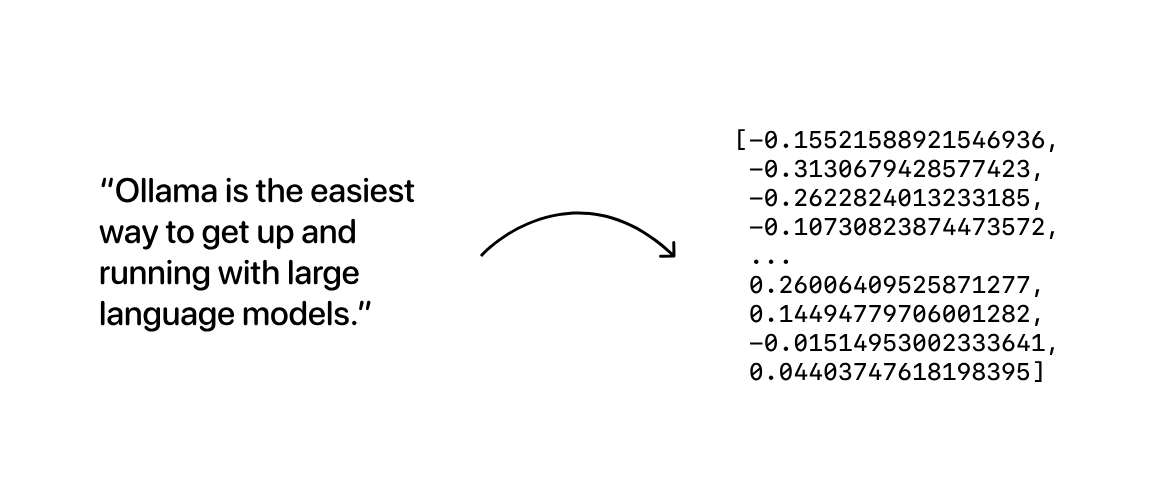
然后,可以将生成的向量嵌入数组存储在数据库中,数据库将对它们进行比较,以搜索含义相似的数据。
注意:当启动 Ollama 之后,Windows会有托盘图标,此时已经启动了 Ollama 的服务,访问 Embedding 时不需要运行 ollama run gemma ,只有访问 chat 时才需要启动一个大模型。
嵌入模型示例
| 模型 | 参数大小 | |
|---|---|---|
| shaw/dmeta-embedding-zh | 4亿 | 查看模型 |
| mxbai-embed-large | 3.34亿 | 查看模型 |
| nomic-embed-text | 1.37 亿 | 查看模型 |
| snowflake-arctic-embed | 3.35亿 | 查看模型 |
| all-minilm | 2300 万 | 查看模型 |
shaw/dmeta-embedding-zh
Dmeta-embedding 是一款跨领域、跨任务、开箱即用的中文 Embedding 模型,适用于搜索、问答、智能客服、LLM+RAG 等各种业务场景,支持使用 Transformers/Sentence-Transformers/Langchain 等工具加载推理。
- Huggingface:https://huggingface.co/DMetaSoul/Dmeta-embedding-zh
- 文档地址:https://ollama.com/shaw/dmeta-embedding-zh
优势特点如下:
- 多任务、场景泛化性能优异,目前已取得 MTEB 中文榜单第二成绩(2024.01.25)
- 模型参数大小仅 400MB,对比参数量超过 GB 级模型,可以极大降低推理成本
- 支持上下文窗口长度达到 1024,对于长文本检索、RAG 等场景更适配
该模型有 4 个不通的版本:
- dmeta-embedding-zh:
shaw/dmeta-embedding-zh是一个参数量只有400M、适用于多种场景的中文Embedding模型,在MTEB基准上取得了优异成绩,尤其适合语义检索、RAG等LLM应用。 - dmeta-embedding-zh-q4:
shaw/dmeta-embedding-zh的 Q4_K_M 量化版本 - dmeta-embedding-zh-small:
shaw/dmeta-embedding-zh-small是比shaw/dmeta-embedding-zh更轻量化的模型,参数不足300M,推理速度提升30%。 - dmeta-embedding-zh-small-q4:
shaw/dmeta-embedding-zh-small的 Q4_K_M 量化版本
ollama pull shaw/dmeta-embedding-zhmxbai-embed-large
截至 2024 年 3 月,该模型在 MTEB 上创下了 Bert-large 尺寸模型的 SOTA 性能记录。它的表现优于 OpenAIs
text-embedding-3-large模型等商业模型,并且与其尺寸 20 倍的模型的性能相当。mxbai-embed-large在没有 MTEB 数据重叠的情况下进行训练,这表明该模型在多个领域、任务和文本长度方面具有很好的泛化能力。
文档地址:https://ollama.com/library/mxbai-embed-large
ollama pull mxbai-embed-largenomic-embed-text
nomic-embed-text 是一个大上下文长度文本编码器,超越了 OpenAI
text-embedding-ada-002,并且text-embedding-3-small在短上下文和长上下文任务上表现优异。
文档地址:https://ollama.com/library/nomic-embed-text
ollama pull nomic-embed-textsnowflake-arctic-embed
snowflake-arctic-embed 是一套文本嵌入模型,专注于创建针对性能优化的高质量检索模型。
这些模型利用现有的开源文本表示模型(例如 bert-base-uncased)进行训练,并在多阶段管道中进行训练以优化其检索性能。
该模型有 5 种参数大小:
- snowflake-arctic-embed:335m(默认)
- snowflake-arctic-embed:137m
- snowflake-arctic-embed:110m
- snowflake-arctic-embed:33m
- snowflake-arctic-embed:22m
文档地址:https://ollama.com/library/snowflake-arctic-embed
ollama pull snowflake-arctic-embedall-minilm
all-minilm 是一款在非常大的句子级数据集上训练的嵌入模型。
文档地址:https://ollama.com/library/all-minilm
ollama pull all-minilm用法
要生成向量嵌入,首先拉取一个模型(以mxbai-embed-large为例):
ollama pull mxbai-embed-large接下来,使用 REST API、Python 或 JavaScript 库 从模型生成向量嵌入:
REST API
curl http://localhost:11434/api/embeddings -d '{
"model": "mxbai-embed-large",
"prompt": "Llamas are members of the camelid family"
}'Python 库
ollama.embeddings(
model='mxbai-embed-large',
prompt='Llamas are members of the camelid family',
)JavaScript 库
ollama.embeddings({
model: 'mxbai-embed-large',
prompt: 'Llamas are members of the camelid family',
})Ollama 还集成了流行工具来支持嵌入工作流程,例如:LangChain和LlamaIndex。
示例
本示例演示如何使用 Ollama 和嵌入模型构建检索增强生成 (RAG) 应用程序。
第 1 步:生成嵌入
pip install ollama chromadb创建一个名为 example.py 的文件 ,内容如下:
import ollama
import chromadb
documents = [
"Llamas are members of the camelid family meaning they're pretty closely related to vicuñas and camels",
"Llamas were first domesticated and used as pack animals 4,000 to 5,000 years ago in the Peruvian highlands",
"Llamas can grow as much as 6 feet tall though the average llama between 5 feet 6 inches and 5 feet 9 inches tall",
"Llamas weigh between 280 and 450 pounds and can carry 25 to 30 percent of their body weight",
"Llamas are vegetarians and have very efficient digestive systems",
"Llamas live to be about 20 years old, though some only live for 15 years and others live to be 30 years old",
]
client = chromadb.Client()
collection = client.create_collection(name="docs")
# store each document in a vector embedding database
for i, d in enumerate(documents):
response = ollama.embeddings(model="mxbai-embed-large", prompt=d)
embedding = response["embedding"]
collection.add(
ids=[str(i)],
embeddings=[embedding],
documents=[d]
)第 2 步:检索
接下来,添加代码以根据示例提示检索最相关的文档:
# an example prompt
prompt = "What animals are llamas related to?"
# generate an embedding for the prompt and retrieve the most relevant doc
response = ollama.embeddings(
prompt=prompt,
model="mxbai-embed-large"
)
results = collection.query(
query_embeddings=[response["embedding"]],
n_results=1
)
data = results['documents'][0][0]第 3 步:生成
最后,使用提示和上一步检索到的文档来生成答案!
# generate a response combining the prompt and data we retrieved in step 2
output = ollama.generate(
model="llama2",
prompt=f"Using this data: {data}. Respond to this prompt: {prompt}"
)
print(output['response'])然后运行代码:
python example.pyWhat animals are llamas related to? Llama 2 将使用以下数据回答提示:
Llamas are members of the camelid family, which means they are closely related to two other animals: vicuñas and camels. All three species belong to the same evolutionary lineage and share many similarities in terms of their physical characteristics, behavior, and genetic makeup. Specifically, llamas are most closely related to vicuñas, with which they share a common ancestor that lived around 20-30 million years ago. Both llamas and vicuñas are members of the family Camelidae, while camels belong to a different family (Dromedary).参考资料:
最后编辑:Ddd4j 更新时间:2026-04-26 23:11
