QAnything

Github:https://github.com/netease-youdao/QAnything/
什么是QAnything?
QAnything (Question and Answer based on Anything) 是致力于支持任意格式文件或数据库的本地知识库问答系统,可断网安装使用。
您的任何格式的本地文件都可以往里扔,即可获得准确、快速、靠谱的问答体验。
目前已支持格式: PDF(pdf),Word(docx),PPT(pptx),XLS(xlsx),Markdown(md),电子邮件(eml),TXT(txt),图片(jpg,jpeg,png),CSV(csv),网页链接(html),更多格式,敬请期待…
特点
- 数据安全,支持全程拔网线安装使用。
- 支持文件类型多,解析成功率高,支持跨语种问答,中英文问答随意切换,无所谓文件是什么语种。
- 支持海量数据问答,两阶段向量排序,解决了大规模数据检索退化的问题,数据越多,效果越好,不限制上传文件数量,检索速度快。
- 硬件友好,默认在纯CPU环境下运行,且win,mac,linux多端支持,除docker外无依赖项。
- 易用性,无需繁琐的配置,一键安装部署,开箱即用,各依赖组件(pdf解析,ocr,embed,rerank等)完全独立,支持自由替换。
- 支持类似Kimi的快速开始模式,无文件聊天模式,仅检索模式,自定义Bot模式。
架构
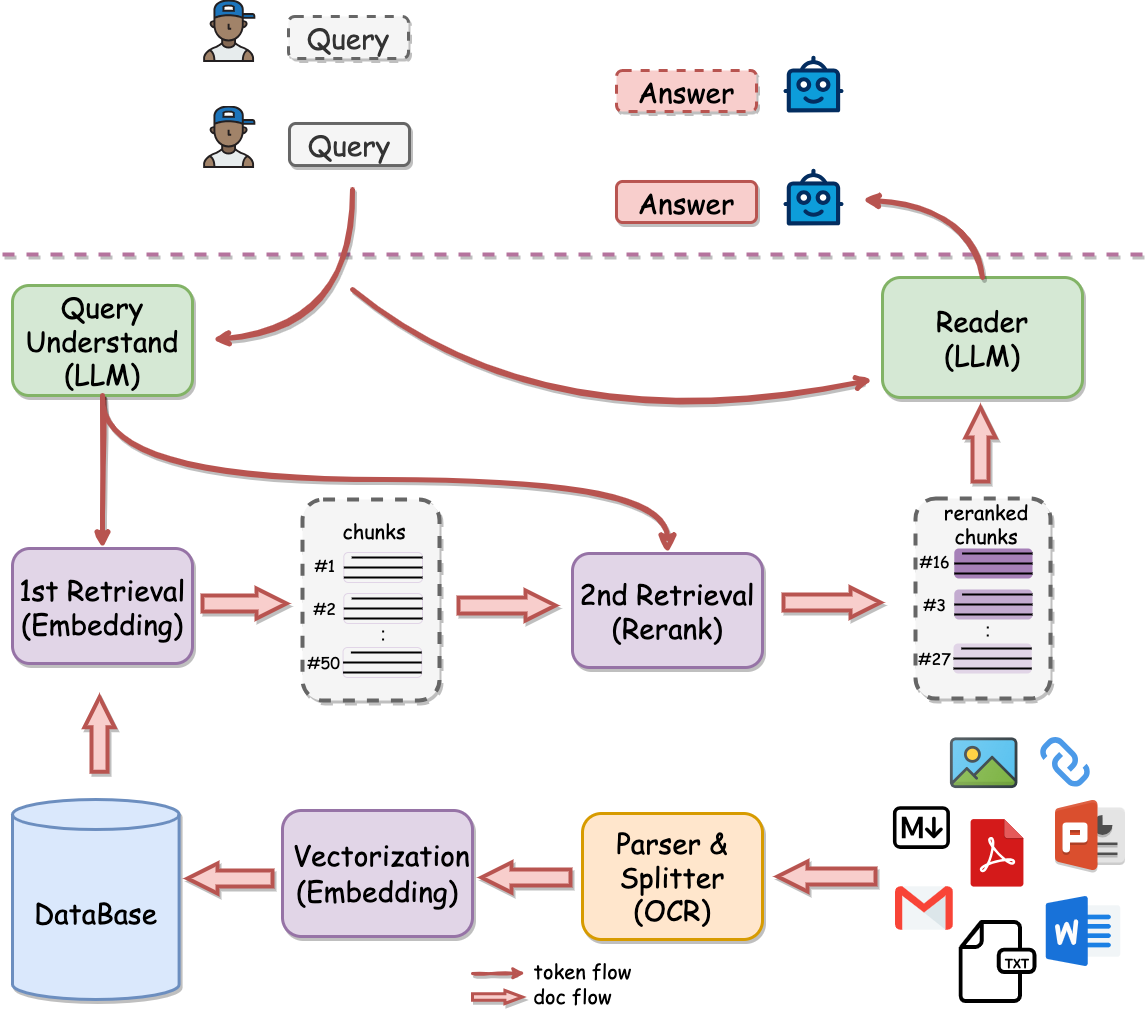
为什么是两阶段检索?
知识库数据量大的场景下两阶段优势非常明显,如果只用一阶段embedding检索,随着数据量增大会出现检索退化的问题,如下图中绿线所示,二阶段rerank重排后能实现准确率稳定增长,即数据越多,效果越好。

QAnything使用的检索组件BCEmbedding有非常强悍的双语和跨语种能力,能消除语义检索里面的中英语言之间的差异,从而实现:
- 强大的双语和跨语种语义表征能力【基于MTEB的语义表征评测指标】。
- 基于LlamaIndex的RAG评测,表现SOTA【基于LlamaIndex的RAG评测指标】。
一阶段检索(embedding)
| 模型名称 | Retrieval | STS | PairClassification | Classification | Reranking | Clustering | 平均 |
|---|---|---|---|---|---|---|---|
| bge-base-en-v1.5 | 37.14 | 55.06 | 75.45 | 59.73 | 43.05 | 37.74 | 47.20 |
| bge-base-zh-v1.5 | 47.60 | 63.72 | 77.40 | 63.38 | 54.85 | 32.56 | 53.60 |
| bge-large-en-v1.5 | 37.15 | 54.09 | 75.00 | 59.24 | 42.68 | 37.32 | 46.82 |
| bge-large-zh-v1.5 | 47.54 | 64.73 | 79.14 | 64.19 | 55.88 | 33.26 | 54.21 |
| jina-embeddings-v2-base-en | 31.58 | 54.28 | 74.84 | 58.42 | 41.16 | 34.67 | 44.29 |
| m3e-base | 46.29 | 63.93 | 71.84 | 64.08 | 52.38 | 37.84 | 53.54 |
| m3e-large | 34.85 | 59.74 | 67.69 | 60.07 | 48.99 | 31.62 | 46.78 |
| bce-embedding-base_v1 | 57.60 | 65.73 | 74.96 | 69.00 | 57.29 | 38.95 | 59.43 |
- 更详细的评测结果详见Embedding模型指标汇总。
二阶段检索(rerank)
| 模型名称 | Reranking | 平均 |
|---|---|---|
| bge-reranker-base | 57.78 | 57.78 |
| bge-reranker-large | 59.69 | 59.69 |
| bce-reranker-base_v1 | 60.06 | 60.06 |
- 更详细的评测结果详见Reranker模型指标汇总
基于LlamaIndex的RAG评测(embedding and rerank)

NOTE:
- 在WithoutReranker列中,我们的bce-embedding-base_v1模型优于所有其他embedding模型。
- 在固定embedding模型的情况下,我们的bce-reranker-base_v1模型达到了最佳表现。
- bce-embedding-base_v1和bce-reranker-base_v1的组合是SOTA。
- 如果想单独使用embedding和rerank请参阅:BCEmbedding
LLM
v2.0版本QAnything不再提供本地大模型,用户可自行接入OpenAI接口兼容的其他开源大模型服务,如ollama, DashScope等。
作者:Ddd4j 创建时间:2024-11-20 13:53
最后编辑:Ddd4j 更新时间:2026-02-27 09:37
最后编辑:Ddd4j 更新时间:2026-02-27 09:37
